type-of-html: High performance type driven html generation.
This is a package candidate release! Here you can preview how this package release will appear once published to the main package index (which can be accomplished via the 'maintain' link below). Please note that once a package has been published to the main package index it cannot be undone! Please consult the package uploading documentation for more information.
Warnings:
- 'ghc-options: -O0' is not needed. Use the --disable-optimization configure flag.
- 'ghc-options: -O2' is rarely needed. Check that it is giving a real benefit and not just imposing longer compile times on your users.
- Exposed modules use unallocated top-level names: Html
This library makes most invalid html documents compile time errors and uses advanced type level features to realise compile time computations.
[Skip to Readme]
Properties
| Versions | 0.2.1.1, 0.3.0.0, 0.4.0.0, 0.4.0.1, 0.4.1.1, 0.5.0.0, 0.5.1.0, 0.5.1.1, 0.5.1.2, 0.5.1.2, 1.0.0.0, 1.0.1.0, 1.0.1.1, 1.1.0.0, 1.2.0.0, 1.3.0.0, 1.3.0.1, 1.3.1.0, 1.3.1.1, 1.3.2.0, 1.3.2.1, 1.3.3.0, 1.3.3.1, 1.3.3.2, 1.3.4.0, 1.4.0.0, 1.4.0.1, 1.4.0.2, 1.4.1.0, 1.5.0.0, 1.5.1.0, 1.5.2.0, 1.6.0.0, 1.6.1.0, 1.6.1.1, 1.6.1.2, 1.6.2.0 |
|---|---|
| Change log | ChangeLog.md |
| Dependencies | base (>=4.10 && <4.11), bytestring, ghc-prim, text [details] |
| License | BSD-3-Clause |
| Copyright | 2017, Florian Knupfer |
| Author | Florian Knupfer |
| Maintainer | fknupfer@gmail.com |
| Category | Language |
| Home page | https://github.com/knupfer/type-of-html |
| Source repo | head: git clone https://github.com/knupfer/type-of-html |
| Uploaded | by knupfer at 2017-09-18T17:27:12Z |
Modules
[Index]
Downloads
- type-of-html-0.5.1.2.tar.gz [browse] (Cabal source package)
- Package description (as included in the package)
Maintainer's Corner
Package maintainers
For package maintainers and hackage trustees
Readme for type-of-html-0.5.1.2
[back to package description]Type of html
type-of-html is a library for generating html in a highly
performant, modular and type safe manner.
Please look at the documentation of the module for an overview of the api: Html
Note that you need at least ghc 8.2.
Typesafety
Part of the html spec is encoded at the typelevel, turning a lot of mistakes into type errors.
Let's check out the /type safety/ in ghci:
>>> td_ (tr_ "a")
<interactive>:1:1: error:
• 'Tr is not a valid child of 'Td
• In the expression: td_ (tr_ "a")
In an equation for ‘it’: it = td_ (tr_ "a")
<interactive>:1:6: error:
• 'Tr can't contain a string
• In the first argument of ‘td_’, namely ‘(tr_ "a")’
In the expression: td_ (tr_ "a")
In an equation for ‘it’: it = td_ (tr_ "a")
>>> tr_ (td_ "a")
<tr><td>a</td></tr>
And
>>> td_A (A.coords_ "a") "b"
<interactive>:1:1: error:
• 'CoordsA is not a valid attribute of 'Td
• In the expression: td_A (A.coords_ "a") "b"
In an equation for ‘it’: it = td_A (A.coords_ "a") "b"
>>> td_A (A.id_ "a") "b"
<td id="a">b</td>
Every parent child relation of html elements is checked against the specification of html and non conforming elements result in compile errors.
The same is true for html attributes.
The checking is a bit lenient at the moment:
- some elements can't contain itself as any descendant: at the moment we look only at direct children. This allows some (quite exotic) invalid html documents.
- some elements change their permitted content based on attributes: we always allow content as if all relevant attributes are set.
Never the less: these cases are seldom. In the vast majority of cases you're only allowed to construct valid html. These restrictions aren't fundamental, they could be turned into compile time errors. Perhaps a future version will be even more strict.
Modularity
Html documents are just ordinary haskell values which can be composed or abstracted over:
>>> let table = table_ . map (tr_ . map td_)
>>> :t table
table :: ('Td ?> a) => [[a]] -> 'Table > ['Tr > ['Td > a]]
>>> table [["A","B"],["C"]]
<table><tr><td>A</td><td>B</td></tr><tr><td>C</td></tr></table>
>>> import Data.Char
>>> html_ . body_ . table $ map (\c -> [[c], show $ ord c]) ['a'..'d']
<html><body><table><tr><td>a</td><td>97</td></tr><tr><td>b</td><td>98</td></tr><tr><td>c</td><td>99</td></tr><tr><td>d</td><td>100</td></tr></table></body></html>
And here's an example module:
{-# LANGUAGE TypeOperators #-}
{-# LANGUAGE DataKinds #-}
module Main where
import Html
import qualified Html.Attribute as A
main :: IO ()
main
= print
. page
$ map td_ [1..(10::Int)]
page
:: 'Tr ?> a
=> a
-> ('Div :@: ('ClassA := String # 'IdA := String))
( 'Div > String
# 'Div > String
# 'Table > 'Tr > a
)
page tds =
div_A (A.class_ "qux" # A.id_ "baz")
( div_ "foo"
# div_ "bar"
# table_ (tr_ tds)
)
Please note that the type of page is inferable, so ask ghc-mod or
whatever you use to write it for you. If you choose not to write the
types, you don't need the language extensions. I strongly suggest
that you don't write type signatures for type-of-html.
All text will be automatically html escaped:
>>> i_ "&"
<i>&</i>
>>> div_A (A.id_ ">") ()
<div id=">"></div>
If you want to opt out, wrap your types into the 'Raw' constructor. This will increase performance, but can be only used with trusted input. You can use this e.g. to embed some blaze-html code into type-of-html.
>>> i_ (Raw "</i><script></script><i>")
<i></i><script></script><i></i>
Performance
type-of-html is a lot faster than blaze-html or than lucid.
Look at the following benchmarks:
Remember this benchmark from blaze-html?
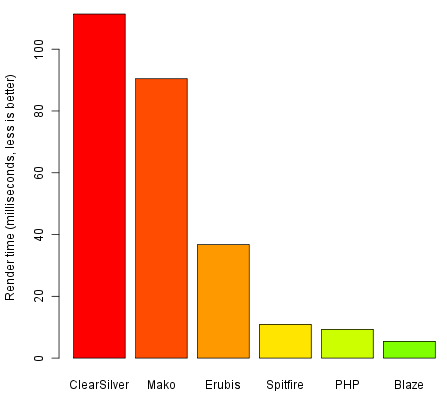
This is comparing blaze with type-of-html:

To look at the exact code of this benchmark look here in the repo. The big table benchmark here is only a 4x4 table. Using a 1000x10 table like on the blaze homepage yields even better relative performance (~9 times faster), but would make the other benchmarks unreadable.
How is this possible? We supercompile lots of parts of the generation process. This is possible thanks to the new features of GHC 8.2: AppendSymbol. We represent tags and attributes as kinds and map these to (a :: [Symbol]) and then fold all neighbouring Symbols with AppendSymbol. Afterwards we reify the Symbols with symbolVal which will be embedded in the executable as Addr#. All this happens at compile time. At runtime we do only generate the content and append Builders.
For example, if you write:
renderText $ tr_ (td_ "test")
The compiler does optimize it to the following (well, unpackCString# doesn't exist for Builder, so it's slightly more complicated):
decodeUtf8 $ toLazyByteString
( Data.ByteString.Builder.unpackCString# "<tr><td>"#
<> builderCString# "test"#
<> Data.ByteString.Builder.unpackCString# "</tr>"#
)
Note that the compiler automatically sees that your string literal
doesn't need utf8 and converts directly the "test"# :: Addr# to an
escaped Builder without any intermediate structure, not even an
allocated bytestring.
renderByteString $ tr_ (td_ "teſt")
Results in
toLazyByteString
( Data.ByteString.Builder.unpackCString# "<tr><td>"#
<> encodeUtf8BuilderEscaped prim (Data.Text.unpackCString# "te\\197\\191t"#)
<> Data.ByteString.Builder.unpackCString# "</tr>"#
)
If you write
renderBuilder $ div_ (div_ ())
The compiler does optimize it to the following:
Data.ByteString.Builder.unpackCString# "<div><div></div></div>"#
This sort of compiletime optimization isn't for free, it'll increase compilation times.
Note that compiling with -O2 results in a ~25% faster binary than
with -O and compiling with -O0 compiles about 15 times faster, so
be sure that you develop with -O0 and benchmark or deploy with
-O2. Be aware, that cabal compiles only with -O if you don't
specify explicitly otherwise.
Even faster
Need for speed? Consider following advise, which is sorted in ascending order of perf gains:
- If you've got attributes or contents of length 1, use a Char
This allows for a more efficient conversion to builder, because we know the length at compile time
div_ 'a'
- If you know for sure that you don't need escaping, use
Raw
This allows for a more efficient conversion builder, because we don't need to escape
div_ (Raw "a")
- If you've got numeric attributes or contents, don't convert it to a string
This allows for a more efficient conversion to builder, because we don't need to escape and don't need to handle utf8
div_ (42 :: Int)
- If you know that an attribute or content is empty, use
()
This allows for more compile time appending and avoids two runtime appends
div_ ()
- If you know for sure a string at compile time which doesn't need
escaping, use a
Proxy Symbol
This allows for more compile time appending and avoids two runtime appends, escaping and conversion to a builder
div_ (Proxy @"hello")
These techniques can have dramatic performance implications,
especially the last two. If you replace for example in the big page with attributes benchmark every string with a Proxy Symbol, it'll run
in 10 ns which is 500 times faster than blaze-html. Looking at core
shows that this is equivalent of directly embedding the entire
resulting html as bytestring in the binary and is therefore the
fastest possible output.
Comparision to lucid and blaze-html
Advantages of type-of-html:
- more or less 10 times faster on a medium sized page
- a lot higher type safety: nearly no invalid document is inhabited
- fewer dependencies
Disadvantages of 'type-of-html':
- a bit noisy syntax (don't write types!)
- sometimes unusual type error messages
- compile times (30sec for a medium sized page, with
-O0only ~2sec) - needs at least ghc 8.2
I'd generally recommend that you put your documents into an extra
module to avoid frequent recompilations. Additionally you can use
type-of-html within an blaze-html document and vice versa. This
allows you to gradually migrate, or only write the hotpath in a more
efficient representation.
Example usage
{-# OPTIONS_GHC -fno-warn-missing-signatures #-}
module Main where
import Html
import Data.Text.Lazy.IO as TL
main :: IO ()
main = TL.putStrLn $ renderText example
example =
html_
( body_
( h1_
( img_
# strong_ "0"
)
# div_
( div_ "1"
)
# div_
( form_
( fieldset_
( div_
( div_
( label_ "a"
# select_
( option_ "b"
# option_ "c"
)
# div_ "d"
)
)
# button_ (i_ "e")
)
)
)
)
)